CIKM2022 参加報告
こんにちは。@shunk031 です。 10 月 17 日から 21 日の 5 日間にアメリカ・アトランタで開催された CIKM2022 に現地参加して発表をしましたので、その参加報告をします。

今回、共著 (2nd author) として採択された short paper のポスター発表を行いました。 1st author の 中川さん が執筆した参加報告は こちら です。 今回発表した研究と聴講して特に印象に残った発表を紹介した後、現地の様子なども合わせて説明します。
- CIKM とは
- CIKM にて発表した内容について
- 印象に残った研究発表
- [Full paper] Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Models
- [Full paper] Incorporating Peer Reviews and Rebuttal Counter-Arguments for Meta-Review Generation
- [Full paper] GROWN+UP: A ''Graph Representation Of a Webpage" Network Utilizing Pre-training
- [Applied research paper; best paper] Real-time Short Video Recommendation on Mobile Devices
- [Applied research paper] e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce
- 印象に残った short paper のリスト
- 開催地アトランタの様子
- まとめ
- 謝辞
CIKM とは
CIKM とは人工知能・データマイニングのメジャーカンファレンスで、今年で 31 回目の開催となります。 この分野のトップカンファレンスである KDD を中心に ICDM, WSDM と同様の分野をカバーしています。

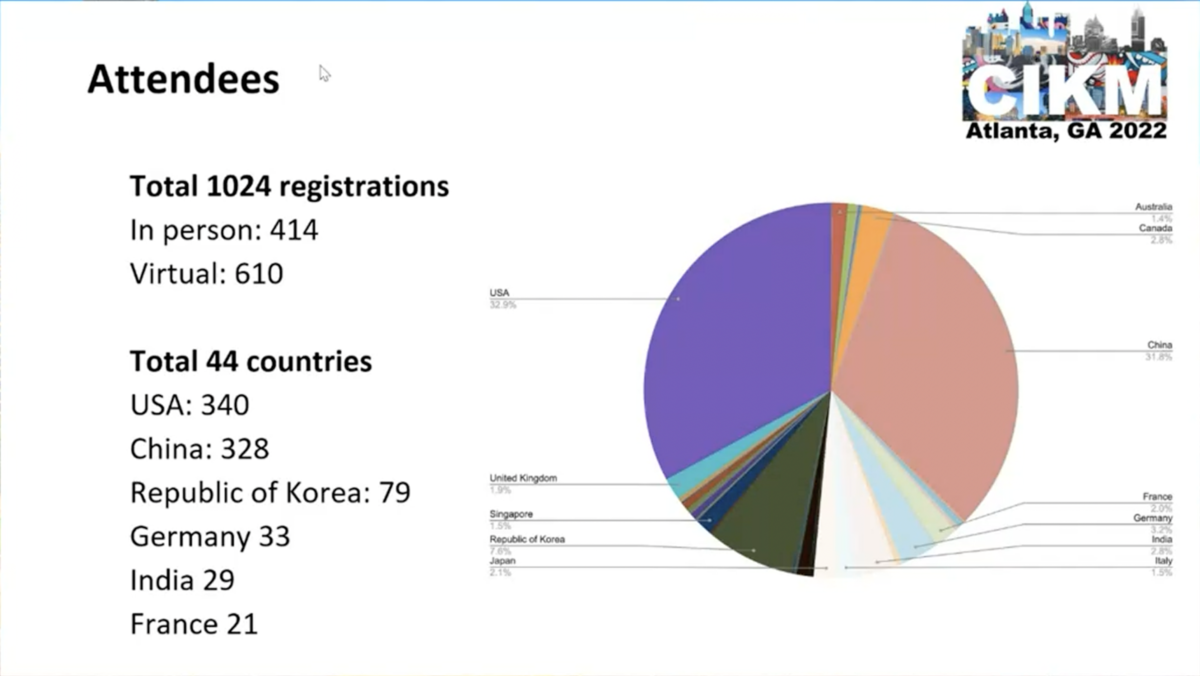
CIKM は full / short & resource / applied research / demo の 4 つの track からなり、それぞれ産業応用に非常に近いポジションで実施された高いクオリティの研究が発表されています。 去年に引き続きハイブリッド形式での開催となり、参加者は 1,024 人(オフライン: 414 人、オンライン: 610 人)でした。 このうち日本からの参加者は 2% に留まっており、データマイニングコミュニティにおける日本のプレゼンスに少し不安が残りました。
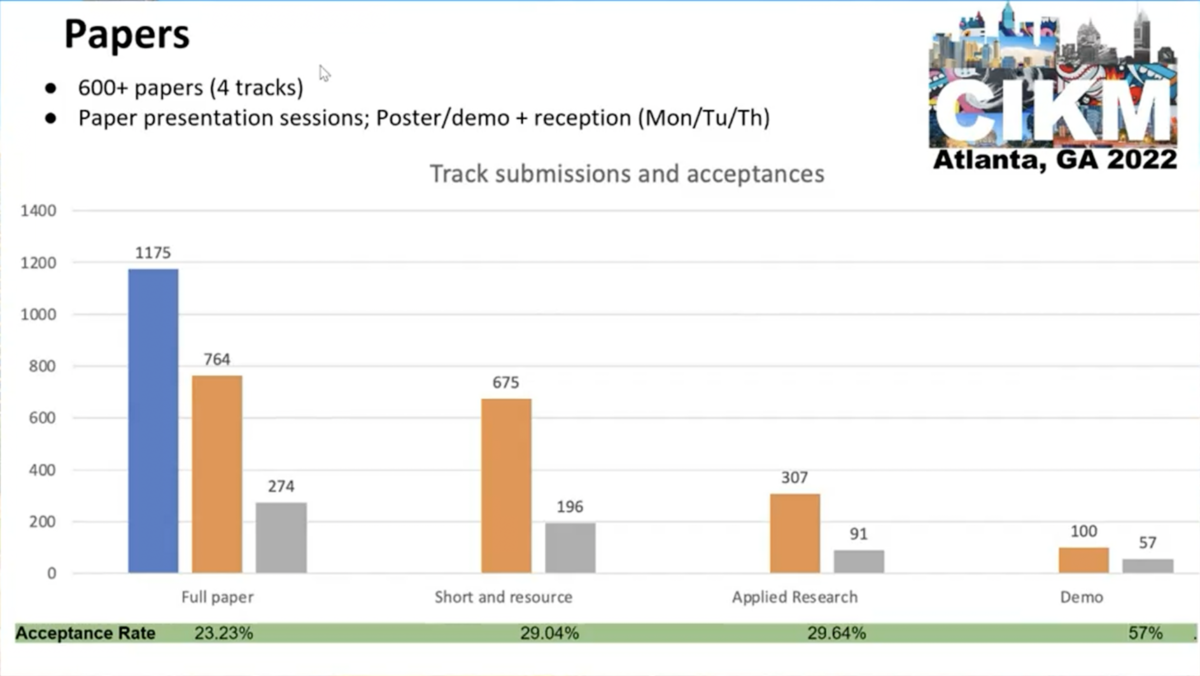
論文採択率は full paper が 23.23% (274/1175)、我々が採択された short & resource paper が 29.04% (196/675)、applied research paper が 29.64% (91/307)、demo paper が 57% (57/100) でした。 概ね採択率が 30 % を下回る competitive な結果となっております。
学会日程 は初日から 4 日目まで main conference と tutorial が並行して開催され、最後の 1 日で workshop が実施されました。
CIKM にて発表した内容について
今回は所属研究室 M1 の 中川さん との共著で short paper track にポスター発表で採択された "Expressions Causing Differences in Emotion Recognition in Social Networking Service Documents" の発表を行いました。 この発表は中川さんの卒論の成果が元になっています。 特に SNS 上でのやり取りにより "書き手" と "読み手" において起きうる感情認識の差に着目し、これらの差を生み出す語を自動的に見つける手法を提案しました。
M1 後輩との共著論文が #CIKM2022 の short paper track にて採択されました!特にSNS上でのやり取りにより "書き手" と "読み手" において起きうる感情認識の差に着目し、これらの差を生み出す語を自動的に見つける手法を提案しました🤖 学部時代の研究成果を CIKM に通しちゃうの、凄すぎる 🎉🎉 https://t.co/1j6hvn62iQ
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年8月2日
We (@nakatuba0626 & I) will present the following poster at #CIKM2022 on Monday, Oct. 17th, 17:30 - 19:00 (EDT). I'm very excited to attend the poster session onsite for the first time in three years 😭 We're confident in the design of this poster 💪 Come say hi to our session 😍 pic.twitter.com/IAf9AGZhFP
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月16日
Ready to present✌️#CIKM2022 pic.twitter.com/2JHKsEGTk1
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月17日

上記はポスター発表の様子です。 非常に多くの参加者が発表を聞きに来て下さり、活発に質疑応答ができました。 私がコロナ禍前にポスター発表した際と同程度まで密な感じでした。 これがポスター発表の醍醐味とも言えますね。 中川さんは今回が初対面ポスター(そして初海外!)であったため最初は戸惑っていましたが、そのあたりは仕事が少なかった 2nd author の私が微妙にアシストできてよかったと感じています。
印象に残った研究発表
CIKM2022 に参加していて印象に残った研究を 5 件 + (full paper 3 件、applied research paper 2 件、short paper 複数件) について紹介します。
[Full paper] Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Models


中国の南京大学と Alibaba との共同研究の成果です。 推薦システムにおいて深層学習技術が広く応用されていますが、推薦システムにおけるモデルの過学習問題についてこれまであまり検討されておりませんでした。 しかしながらこの過学習問題は非常に重要な問題であることはコミュニティ全体で知られています。 本研究では、推薦システムで重要なクリック率 (click-through rate; CTR) 予測において、モデル訓練時に 2 epoch 目の開始時に予測性能が劇的に低下する(過学習する)という、1 epoch overfitting problem について議論しています。 このような現象は、CTR 予測モデルの実世界応用で頻繁に遭遇していると思います。 この 1 epoch overfitting problem について、本研究では alibaba のディスプレイ広告システムから収集された本番環境データセットに対して広範囲な実験を行っています。 評価結果から使用するモデルの構造、最適化手法、特徴量のスパース度合いが 1 epoch overfitting に密接に関係していることが報告されています。
日々新たな CTR 予測モデルの提案がされてきていますが、そういったモデルの根本的な問題について実際の大規模データを用いて分析している例は非常に参考になります。 モデル関連のハイパーパラメータ (モデルの構造やパラメータ数、活性化関数、バッチサイズ、最適化手法、正則化手法) と入力特徴関連のハイパーパラメータ (ユーザー特徴、行動特徴、アイテム特徴、コンテキスト特徴) の側面から丁寧に分析および議論されており、CTR 予測モデルを構築している機械学習エンジニアの方に特に参考になる情報が記載されています。
[Full paper] Incorporating Peer Reviews and Rebuttal Counter-Arguments for Meta-Review Generation


国立台湾大学の研究チームの成果です。 みなさん御存知の通り、査読プロセスは研究論文を複数の査読者が評価する、研究において重要な過程の一部分です。 コンピュータサイエンス分野のトップカンファレンスではリバッタルの機会が設けられており、著者が査読者のレビューに対して自身の研究について議論・反論します。 最終的な採択不採択の決定は、一般的に meta-review の内容によって決まります。 これまでの研究では、Transformer ベースのモデルを用いた要約モデルを訓練し、meta-review 生成を生成する技術が検討されてきました。 しかし、反論の内容や、議論の説得力が最終決定に影響を与える重要な役割を果たす、レビューと反論の間の相互作用を考慮したものはほとんどない。 著者らは、査読者の意見と著者の反応をうまく整理した包括的な meta-review を生成するために、査読者と著者間の議論だけでなく、査読者間の議論も含めた複雑な議論構造を明示的にモデル化できる新しい生成モデルを提案しています。 実験の結果、著者らのモデルは自動評価と人間による評価の両方においてベースラインを上回り、提案手法の有効性を実証しています。 訓練したモデルが生成した meta-review は、最初に論文を要約し、次に最終決定のためにレビュアーと著者の議論を締めくくるという書き方を学んでいます。 提案法はさらに詳細な情報を生成可能になっていることが示唆されています。
[Full paper] GROWN+UP: A ''Graph Representation Of a Webpage" Network Utilizing Pre-training

Klass Engineering & Solutions というシンガポールの企業の成果です。 大規模事前学習済みニューラルネットワークは自然言語処理分野やコンピュータビジョン分野における多くの downstream タスクでの成功に不可欠です。 しかしながら情報検索分野では、ウェブページを適切に解析できる柔軟で強力な事前学習済みモデルが、前述の分野とは異なって有望なものが存在しておりません。 そのため、ウェブページからコンテンツ抽出をしたり、データマイニングしたりといった一般的な機械学習タスクは、まだ未開拓のままであると著者らは考えているようです。 以上より、著者らはウェブページの構造を取り込み、ラベル付けされていない膨大なデータに対して自己教師付き事前学習を行い、ウェブページを扱う任意のタスクに効果的に fine-tuning できる、深層グラフニューラルネットワークを元にした特徴抽出器を導入することで、こうしたギャップを埋めることを目的としています。 提案されている事前学習済みモデルは、ウェブページの定型文除去タスク (webpage boilerplate removal) とジャンル分類という全く異なる 2 つのベンチマークにおいて、複数のデータセットを用いて最先端の結果を達成したことを示しています。 この結果は他の多様な downstream タスクへの応用可能性を示唆しているものだと感じました。
[Applied research paper; best paper] Real-time Short Video Recommendation on Mobile Devices



Kuaishou Inc. という中国の企業の成果です。 Applied research track の best paper です。 短編動画アプリケーションは近年何億人ものユーザを魅了し、多様なコンテンツで様々なニーズを満たしています。 ユーザは通常、モバイルデバイス上で多様なトピックの短編動画を短時間で視聴し、視聴した動画に対して明示的または暗黙的にフィードバックしています。 推薦システムは変化するユーザの興味を満たすために、ユーザの嗜好をリアルタイムに検出する必要があります。 従来、推薦システムはサーバ側に配置されており、クライアントからのリクエストに対して、ランク付けされた動画リストを返していました。 よって、サーバ側に配置された推薦システムは、クライアントからのリクエストごとに動画のランキングリストを返すため、次のリクエストの前に、ユーザのリアルタイムなフィードバックに従って推薦結果を調整することが困難です。 また、クライアントとサーバ感の通信遅延のため、ユーザのリアルタイムなフィードバックを即座に利用することも難しいです。 しかしながらこうしたフェードバックを利用できない場合、ユーザが動画を視聴している間に興味のコンテキストが変化してしまうため、サーバ側で計算したランキングが不正確なものとなってしまいます。 本論文では、これらの問題を解決するため、モバイルデバイス上で短編動画推薦を行う新たな枠組みを提案しています。 具体的には、サーバ側の推薦結果をリアルタイムでリランキングできるように、モバイルデバイス上でも動作するような軽量なランキングモデルを設計・導入しています。 その際に、視聴した動画に対するユーザのリアルタイムのフィードバックと、クライアント固有のリアルタイム特徴を利用することで予測性能を高める工夫がされています。 また、より高い予測性能を実現するために、候補動画間の相互関係を考慮し、適応的な beam search に基づく文脈を考慮したリランキング手法を提案しています。 提案フレームワークは、10 億ユーザ規模の短編動画アプリケーションである kuaishou に展開されており、効果のある視聴回数・いいね数、フォロー数をそれぞれ 1.28%・8.22%・13.6% 向上したことを確認しています。
[Applied research paper] e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce

韓国の NAVER Shopping チームの成果です。 E コマースにおける検索や推薦のアプリケーションにおいて、商品情報の視覚的および言語的表現の理解が不可欠です。 オンラインショッピングプラットフォームの中枢として、ラベル付けされていない生の商品テキストと画像のアラインメントを学習するような vision and language モデルを constractive learning で学習させる枠組みを提案しています。 大規模な表現学習モデルを学習するために用いた技術が紹介されており、ドメイン固有の課題に対処するための解決策について議論されています。 著者らは、カテゴリ分類、属性抽出、商品マッチング、商品クラスタリング、大人向け商品認識などの多様な下流タスクの backbone として、提案する事前学習済みモデルを用いて性能を評価しています。 実験の結果、提案手法は単一モダリティと複数モダリティの両方に関して、各 downstream タスクでベースラインを上回る性能を示しています。
印象に残った short paper のリスト
印象に残った short paper のリストを以下に載せます。 詳細については言及しませんが、full paper にはない研究の原石たちがたくさん見つけました。
- Texture BERT for Cross-modal Texture Image Retrieval
- Visual Encoding and Debiasing for CTR Prediction
- Multi-scale Multi-modal Dictionary BERT For Effective Text-image Retrieval in Multimedia Advertising
- Interpretability of BERT Latent Space through Knowledge Graphs
- Semi-Supervised Learning with Data Augmentation for Tabular Data
- Deep Presentation Bias Integrated Framework for CTR Prediction
- See Clicks Differently: Modeling User Clicking Alternatively with Multi Classifiers for CTR Prediction
開催地アトランタの様子
以下は開催地アトランタについて、観光名所を中心にツイート形式で一言コメントとともに紹介します。
CIKM2022 の会場
#CIKM2022 1st day 😎 (@ The Westin Peachtree Plaza in Atlanta, GA) https://t.co/QTt7ZSYUgu
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月17日
I'm attending #CIKM2022 in person. This is my first international conference. It's so exciting! pic.twitter.com/sncCAKTGmT
— なかつば (@nakatuba0626) 2022年10月17日
キング牧師歴史地区
- 結構こわかった
キング牧師歴史地区に行ったが、そこはかとない治安の悪さを感じた(夜行ったら終わりそう) (@ Dr Martin Luther King Jr National Historic Site - @natlparkservice in Atlanta, GA) https://t.co/FjbCwNExvd pic.twitter.com/ubnpoYehyN
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
CNN 本社
- ビルのなかにビルがあって謎
でかい畳込みニューラルネットワーク (@ CNNセンター - @cnncenter in Atlanta, GA) https://t.co/WfgyVD8eRP pic.twitter.com/2kz1c2Yw4N
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月20日
100 周年オリンピック公園
- 無限にリスさんいた
でかい公園(足元のレンガに名前らしきものがたくさん彫られていて、これ踏みながら歩くの微妙な気持ちに…😂) (@ Centennial Olympic Park - @centennial_park in Atlanta, GA) https://t.co/ANQPuQt4kN pic.twitter.com/CAkregycdh
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
コカ・コーラ博物館
- コーラ関連の飲み物が無限に飲めます
- 入場料が $20 になってました
Stable diffusion で生成されたような絵を見ています (@ World of Coca-Cola in Atlanta, GA) https://t.co/UqDTLSV4t4 pic.twitter.com/MFxkbKn2Pq
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月20日
ジョージア工科大学
- レンガ造りの建物かっこいい
僕も Lime で通学したいよ〜〜って言った(キャンパス広い) (@ ジョージア工科大学 - @georgiatech in Atlanta, GA) https://t.co/4RTKlyXZZA pic.twitter.com/dbNEcnDDcF
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
Barnes & Noble at Georgia Tech
ジョージア工科大学生なのでパーカーを買いました(アトランタで着る服がなくなったので助かる) (@ Georgia Tech Bookstore in Atlanta, GA) https://t.co/fT7gxNb5E8 pic.twitter.com/Y08D7vuAaO
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
オークランド墓地
- みんなカジュアルに墓場でお散歩してるんですね
オークランド墓地とグラサンのぼく😎 (at @OaklandCemetery in Atlanta, GA) https://t.co/sIjMcCIrzs pic.twitter.com/q84LRyrOXV
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月23日
まとめ
アトランタにて開催されたデータマイニングのメジャーカンファレンス CIKM2022 にて共著のポスター発表をしました。 本成果は優秀な研究室後輩 M1 の中川さんが頑張ったものであり、とても素晴らしい発表をしてくれました。 非常にユニークで面白い発表を多数聞けたのも収穫が多かったです。 久しぶりにアメリカに来ることができてよかったですが、円安が厳しいのが少し気になりながら生活していました。 CIKM のような学会に、また発表参加できるように研究をやっていきたいです。
謝辞
本研究の一部は JSPS 科研費 21J14143 の助成を受けております。