【外部発表】[IR Reading 2022秋 論文紹介] Expressions Causing Differences in Emotion Recognition in Social Networking Service Documents (CIKM'22)
こんにちは。 @shunk031 です。
11月12日に IR Reading 2022秋(オンライン)にて我々が CIKM2022 にて発表した Expressions Causing Differences in Emotion Recognitionin Social Networking Service Documents (CIKM2022)というタイトルで登壇しました。
登壇概要とそのときの資料を載せます。
登壇概要
- [IR Reading 2022秋 論文紹介] Expressions Causing Differences in Emotion Recognition in Social Networking Service Documents (CIKM'22) / IR Reading 2022 Autumn
- https://sigir.jp/post/2022-11-12-irreading_2022fall/
発表資料
関連情報
- CIKM2022 参加報告
CIKM2022 参加報告
こんにちは。@shunk031 です。 10 月 17 日から 21 日の 5 日間にアメリカ・アトランタで開催された CIKM2022 に現地参加して発表をしましたので、その参加報告をします。

今回、共著 (2nd author) として採択された short paper のポスター発表を行いました。 1st author の 中川さん が執筆した参加報告は こちら です。 今回発表した研究と聴講して特に印象に残った発表を紹介した後、現地の様子なども合わせて説明します。
- CIKM とは
- CIKM にて発表した内容について
- 印象に残った研究発表
- [Full paper] Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Models
- [Full paper] Incorporating Peer Reviews and Rebuttal Counter-Arguments for Meta-Review Generation
- [Full paper] GROWN+UP: A ''Graph Representation Of a Webpage" Network Utilizing Pre-training
- [Applied research paper; best paper] Real-time Short Video Recommendation on Mobile Devices
- [Applied research paper] e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce
- 印象に残った short paper のリスト
- 開催地アトランタの様子
- まとめ
- 謝辞
CIKM とは
CIKM とは人工知能・データマイニングのメジャーカンファレンスで、今年で 31 回目の開催となります。 この分野のトップカンファレンスである KDD を中心に ICDM, WSDM と同様の分野をカバーしています。

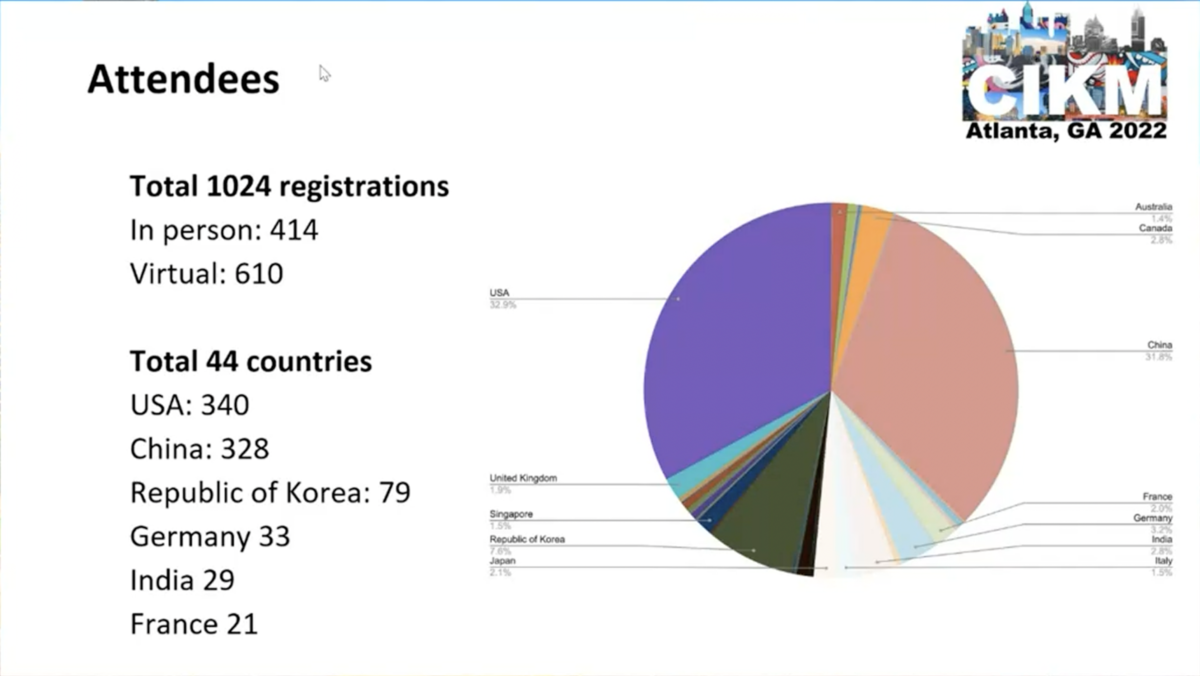
CIKM は full / short & resource / applied research / demo の 4 つの track からなり、それぞれ産業応用に非常に近いポジションで実施された高いクオリティの研究が発表されています。 去年に引き続きハイブリッド形式での開催となり、参加者は 1,024 人(オフライン: 414 人、オンライン: 610 人)でした。 このうち日本からの参加者は 2% に留まっており、データマイニングコミュニティにおける日本のプレゼンスに少し不安が残りました。
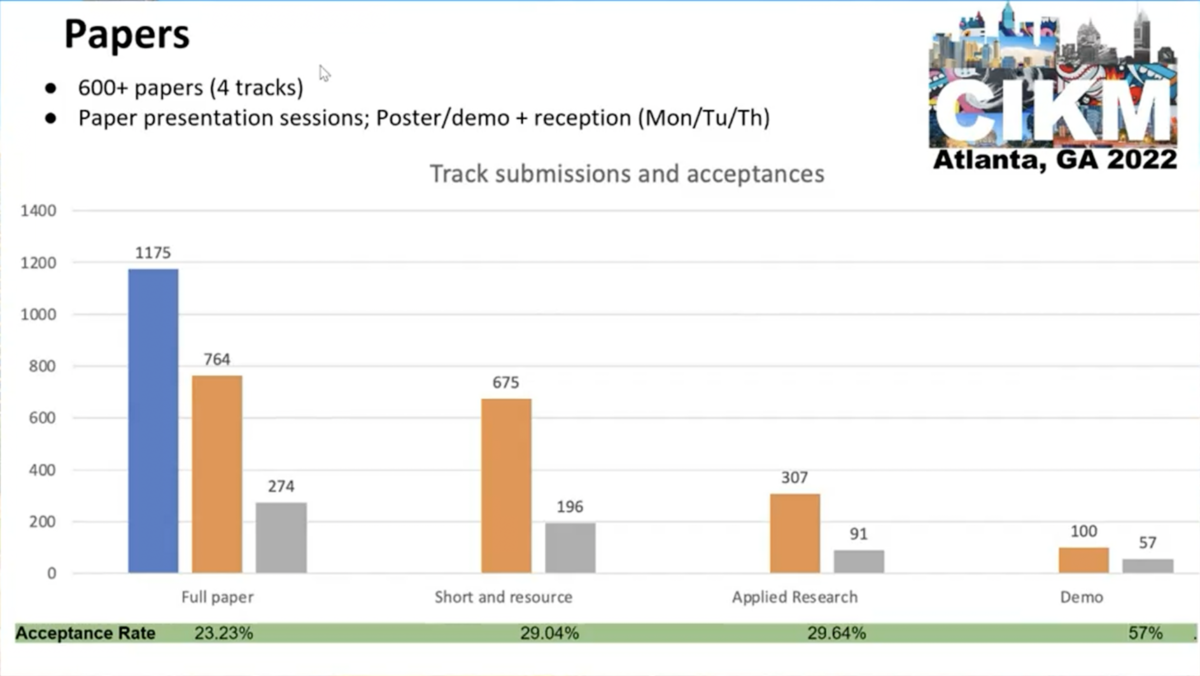
論文採択率は full paper が 23.23% (274/1175)、我々が採択された short & resource paper が 29.04% (196/675)、applied research paper が 29.64% (91/307)、demo paper が 57% (57/100) でした。 概ね採択率が 30 % を下回る competitive な結果となっております。
学会日程 は初日から 4 日目まで main conference と tutorial が並行して開催され、最後の 1 日で workshop が実施されました。
CIKM にて発表した内容について
今回は所属研究室 M1 の 中川さん との共著で short paper track にポスター発表で採択された "Expressions Causing Differences in Emotion Recognition in Social Networking Service Documents" の発表を行いました。 この発表は中川さんの卒論の成果が元になっています。 特に SNS 上でのやり取りにより "書き手" と "読み手" において起きうる感情認識の差に着目し、これらの差を生み出す語を自動的に見つける手法を提案しました。
M1 後輩との共著論文が #CIKM2022 の short paper track にて採択されました!特にSNS上でのやり取りにより "書き手" と "読み手" において起きうる感情認識の差に着目し、これらの差を生み出す語を自動的に見つける手法を提案しました🤖 学部時代の研究成果を CIKM に通しちゃうの、凄すぎる 🎉🎉 https://t.co/1j6hvn62iQ
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年8月2日
We (@nakatuba0626 & I) will present the following poster at #CIKM2022 on Monday, Oct. 17th, 17:30 - 19:00 (EDT). I'm very excited to attend the poster session onsite for the first time in three years 😭 We're confident in the design of this poster 💪 Come say hi to our session 😍 pic.twitter.com/IAf9AGZhFP
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月16日
Ready to present✌️#CIKM2022 pic.twitter.com/2JHKsEGTk1
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月17日

上記はポスター発表の様子です。 非常に多くの参加者が発表を聞きに来て下さり、活発に質疑応答ができました。 私がコロナ禍前にポスター発表した際と同程度まで密な感じでした。 これがポスター発表の醍醐味とも言えますね。 中川さんは今回が初対面ポスター(そして初海外!)であったため最初は戸惑っていましたが、そのあたりは仕事が少なかった 2nd author の私が微妙にアシストできてよかったと感じています。
印象に残った研究発表
CIKM2022 に参加していて印象に残った研究を 5 件 + (full paper 3 件、applied research paper 2 件、short paper 複数件) について紹介します。
[Full paper] Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Models


中国の南京大学と Alibaba との共同研究の成果です。 推薦システムにおいて深層学習技術が広く応用されていますが、推薦システムにおけるモデルの過学習問題についてこれまであまり検討されておりませんでした。 しかしながらこの過学習問題は非常に重要な問題であることはコミュニティ全体で知られています。 本研究では、推薦システムで重要なクリック率 (click-through rate; CTR) 予測において、モデル訓練時に 2 epoch 目の開始時に予測性能が劇的に低下する(過学習する)という、1 epoch overfitting problem について議論しています。 このような現象は、CTR 予測モデルの実世界応用で頻繁に遭遇していると思います。 この 1 epoch overfitting problem について、本研究では alibaba のディスプレイ広告システムから収集された本番環境データセットに対して広範囲な実験を行っています。 評価結果から使用するモデルの構造、最適化手法、特徴量のスパース度合いが 1 epoch overfitting に密接に関係していることが報告されています。
日々新たな CTR 予測モデルの提案がされてきていますが、そういったモデルの根本的な問題について実際の大規模データを用いて分析している例は非常に参考になります。 モデル関連のハイパーパラメータ (モデルの構造やパラメータ数、活性化関数、バッチサイズ、最適化手法、正則化手法) と入力特徴関連のハイパーパラメータ (ユーザー特徴、行動特徴、アイテム特徴、コンテキスト特徴) の側面から丁寧に分析および議論されており、CTR 予測モデルを構築している機械学習エンジニアの方に特に参考になる情報が記載されています。
[Full paper] Incorporating Peer Reviews and Rebuttal Counter-Arguments for Meta-Review Generation


国立台湾大学の研究チームの成果です。 みなさん御存知の通り、査読プロセスは研究論文を複数の査読者が評価する、研究において重要な過程の一部分です。 コンピュータサイエンス分野のトップカンファレンスではリバッタルの機会が設けられており、著者が査読者のレビューに対して自身の研究について議論・反論します。 最終的な採択不採択の決定は、一般的に meta-review の内容によって決まります。 これまでの研究では、Transformer ベースのモデルを用いた要約モデルを訓練し、meta-review 生成を生成する技術が検討されてきました。 しかし、反論の内容や、議論の説得力が最終決定に影響を与える重要な役割を果たす、レビューと反論の間の相互作用を考慮したものはほとんどない。 著者らは、査読者の意見と著者の反応をうまく整理した包括的な meta-review を生成するために、査読者と著者間の議論だけでなく、査読者間の議論も含めた複雑な議論構造を明示的にモデル化できる新しい生成モデルを提案しています。 実験の結果、著者らのモデルは自動評価と人間による評価の両方においてベースラインを上回り、提案手法の有効性を実証しています。 訓練したモデルが生成した meta-review は、最初に論文を要約し、次に最終決定のためにレビュアーと著者の議論を締めくくるという書き方を学んでいます。 提案法はさらに詳細な情報を生成可能になっていることが示唆されています。
[Full paper] GROWN+UP: A ''Graph Representation Of a Webpage" Network Utilizing Pre-training

Klass Engineering & Solutions というシンガポールの企業の成果です。 大規模事前学習済みニューラルネットワークは自然言語処理分野やコンピュータビジョン分野における多くの downstream タスクでの成功に不可欠です。 しかしながら情報検索分野では、ウェブページを適切に解析できる柔軟で強力な事前学習済みモデルが、前述の分野とは異なって有望なものが存在しておりません。 そのため、ウェブページからコンテンツ抽出をしたり、データマイニングしたりといった一般的な機械学習タスクは、まだ未開拓のままであると著者らは考えているようです。 以上より、著者らはウェブページの構造を取り込み、ラベル付けされていない膨大なデータに対して自己教師付き事前学習を行い、ウェブページを扱う任意のタスクに効果的に fine-tuning できる、深層グラフニューラルネットワークを元にした特徴抽出器を導入することで、こうしたギャップを埋めることを目的としています。 提案されている事前学習済みモデルは、ウェブページの定型文除去タスク (webpage boilerplate removal) とジャンル分類という全く異なる 2 つのベンチマークにおいて、複数のデータセットを用いて最先端の結果を達成したことを示しています。 この結果は他の多様な downstream タスクへの応用可能性を示唆しているものだと感じました。
[Applied research paper; best paper] Real-time Short Video Recommendation on Mobile Devices



Kuaishou Inc. という中国の企業の成果です。 Applied research track の best paper です。 短編動画アプリケーションは近年何億人ものユーザを魅了し、多様なコンテンツで様々なニーズを満たしています。 ユーザは通常、モバイルデバイス上で多様なトピックの短編動画を短時間で視聴し、視聴した動画に対して明示的または暗黙的にフィードバックしています。 推薦システムは変化するユーザの興味を満たすために、ユーザの嗜好をリアルタイムに検出する必要があります。 従来、推薦システムはサーバ側に配置されており、クライアントからのリクエストに対して、ランク付けされた動画リストを返していました。 よって、サーバ側に配置された推薦システムは、クライアントからのリクエストごとに動画のランキングリストを返すため、次のリクエストの前に、ユーザのリアルタイムなフィードバックに従って推薦結果を調整することが困難です。 また、クライアントとサーバ感の通信遅延のため、ユーザのリアルタイムなフィードバックを即座に利用することも難しいです。 しかしながらこうしたフェードバックを利用できない場合、ユーザが動画を視聴している間に興味のコンテキストが変化してしまうため、サーバ側で計算したランキングが不正確なものとなってしまいます。 本論文では、これらの問題を解決するため、モバイルデバイス上で短編動画推薦を行う新たな枠組みを提案しています。 具体的には、サーバ側の推薦結果をリアルタイムでリランキングできるように、モバイルデバイス上でも動作するような軽量なランキングモデルを設計・導入しています。 その際に、視聴した動画に対するユーザのリアルタイムのフィードバックと、クライアント固有のリアルタイム特徴を利用することで予測性能を高める工夫がされています。 また、より高い予測性能を実現するために、候補動画間の相互関係を考慮し、適応的な beam search に基づく文脈を考慮したリランキング手法を提案しています。 提案フレームワークは、10 億ユーザ規模の短編動画アプリケーションである kuaishou に展開されており、効果のある視聴回数・いいね数、フォロー数をそれぞれ 1.28%・8.22%・13.6% 向上したことを確認しています。
[Applied research paper] e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce

韓国の NAVER Shopping チームの成果です。 E コマースにおける検索や推薦のアプリケーションにおいて、商品情報の視覚的および言語的表現の理解が不可欠です。 オンラインショッピングプラットフォームの中枢として、ラベル付けされていない生の商品テキストと画像のアラインメントを学習するような vision and language モデルを constractive learning で学習させる枠組みを提案しています。 大規模な表現学習モデルを学習するために用いた技術が紹介されており、ドメイン固有の課題に対処するための解決策について議論されています。 著者らは、カテゴリ分類、属性抽出、商品マッチング、商品クラスタリング、大人向け商品認識などの多様な下流タスクの backbone として、提案する事前学習済みモデルを用いて性能を評価しています。 実験の結果、提案手法は単一モダリティと複数モダリティの両方に関して、各 downstream タスクでベースラインを上回る性能を示しています。
印象に残った short paper のリスト
印象に残った short paper のリストを以下に載せます。 詳細については言及しませんが、full paper にはない研究の原石たちがたくさん見つけました。
- Texture BERT for Cross-modal Texture Image Retrieval
- Visual Encoding and Debiasing for CTR Prediction
- Multi-scale Multi-modal Dictionary BERT For Effective Text-image Retrieval in Multimedia Advertising
- Interpretability of BERT Latent Space through Knowledge Graphs
- Semi-Supervised Learning with Data Augmentation for Tabular Data
- Deep Presentation Bias Integrated Framework for CTR Prediction
- See Clicks Differently: Modeling User Clicking Alternatively with Multi Classifiers for CTR Prediction
開催地アトランタの様子
以下は開催地アトランタについて、観光名所を中心にツイート形式で一言コメントとともに紹介します。
CIKM2022 の会場
#CIKM2022 1st day 😎 (@ The Westin Peachtree Plaza in Atlanta, GA) https://t.co/QTt7ZSYUgu
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月17日
I'm attending #CIKM2022 in person. This is my first international conference. It's so exciting! pic.twitter.com/sncCAKTGmT
— なかつば (@nakatuba0626) 2022年10月17日
キング牧師歴史地区
- 結構こわかった
キング牧師歴史地区に行ったが、そこはかとない治安の悪さを感じた(夜行ったら終わりそう) (@ Dr Martin Luther King Jr National Historic Site - @natlparkservice in Atlanta, GA) https://t.co/FjbCwNExvd pic.twitter.com/ubnpoYehyN
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
CNN 本社
- ビルのなかにビルがあって謎
でかい畳込みニューラルネットワーク (@ CNNセンター - @cnncenter in Atlanta, GA) https://t.co/WfgyVD8eRP pic.twitter.com/2kz1c2Yw4N
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月20日
100 周年オリンピック公園
- 無限にリスさんいた
でかい公園(足元のレンガに名前らしきものがたくさん彫られていて、これ踏みながら歩くの微妙な気持ちに…😂) (@ Centennial Olympic Park - @centennial_park in Atlanta, GA) https://t.co/ANQPuQt4kN pic.twitter.com/CAkregycdh
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
コカ・コーラ博物館
- コーラ関連の飲み物が無限に飲めます
- 入場料が $20 になってました
Stable diffusion で生成されたような絵を見ています (@ World of Coca-Cola in Atlanta, GA) https://t.co/UqDTLSV4t4 pic.twitter.com/MFxkbKn2Pq
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月20日
ジョージア工科大学
- レンガ造りの建物かっこいい
僕も Lime で通学したいよ〜〜って言った(キャンパス広い) (@ ジョージア工科大学 - @georgiatech in Atlanta, GA) https://t.co/4RTKlyXZZA pic.twitter.com/dbNEcnDDcF
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
Barnes & Noble at Georgia Tech
ジョージア工科大学生なのでパーカーを買いました(アトランタで着る服がなくなったので助かる) (@ Georgia Tech Bookstore in Atlanta, GA) https://t.co/fT7gxNb5E8 pic.twitter.com/Y08D7vuAaO
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月22日
オークランド墓地
- みんなカジュアルに墓場でお散歩してるんですね
オークランド墓地とグラサンのぼく😎 (at @OaklandCemetery in Atlanta, GA) https://t.co/sIjMcCIrzs pic.twitter.com/q84LRyrOXV
— しゅんけー@CIKM'22🇺🇸 (@shunk031) 2022年10月23日
まとめ
アトランタにて開催されたデータマイニングのメジャーカンファレンス CIKM2022 にて共著のポスター発表をしました。 本成果は優秀な研究室後輩 M1 の中川さんが頑張ったものであり、とても素晴らしい発表をしてくれました。 非常にユニークで面白い発表を多数聞けたのも収穫が多かったです。 久しぶりにアメリカに来ることができてよかったですが、円安が厳しいのが少し気になりながら生活していました。 CIKM のような学会に、また発表参加できるように研究をやっていきたいです。
謝辞
本研究の一部は JSPS 科研費 21J14143 の助成を受けております。
【外部発表】NLPの研究を加速させるAllenNLP入門
【外部発表】私の学振DC2体験談
こんにちは。@shunk031です。 4月1日に法政大学の学内で開催された2023(令和5)年度 日本学術振興会特別研究員(DC1・DC2)申請に関する セミナーにて講演する機会がありましたので、その時の発表資料を載せます。
発表資料
イベント: 2023(令和5)年度 日本学術振興会特別研究員(DC1・DC2)申請に関する セミナー

2021年の振り返り
こんにちは。@shunk031 です。クリスマスにニューラルネットワーク "力" をお願いしましたが、何も貰えませんでした。 サンタさんは Hinton 先生ではないみたいです。 毎年同じお願いをしている気がします。 2021 年をツイートベースで振り返ります。

各月の活動
1 月
やっていく気持ちを表明していました。
あけましておめでとうございます🎉
— しゅんけー (@shunk031) 2020年12月31日
今年も好きなこと(研究)だけをやっていきます。引き続きよろしくお願いします。
M1 Macbook Pro を購入
4 年ほど使った Intel Macbook Pro から乗り換え。充電の持ちが非常によく、外で論文を書くぐらいならば 2 日ぐらい充電しなくても大丈夫です。電源のあるカフェを探すことはほとんどなくなりました。
My new gear ... M1 Macbook Pro ちゃん😘 pic.twitter.com/iZPIrFKEl2
— しゅんけー (@shunk031) 2021年1月11日
M1 Macbook、ChromeでOverleaf開いて論文執筆するぐらいだと全く充電減らない。これはカフェで「充電なくなったから帰るか〜」ができないやつだ。
— しゅんけー (@shunk031) 2021年1月16日
言語処理学会全国大会 論文投稿
今年は主著 x1、共著 x1 でした。去年の主著 x1、共著 x3(うち留学生 x1)で並行して執筆していたときはかなりしんどかったです。
submitted! 今年も無事言語処理学会 全国大会の原稿を投稿できた
— しゅんけー (@shunk031) 2021年1月15日
博士課程コースワーク 取り組み
弊研究科の博士課程の学生はコースワークなる科目があり、学科内の任意の先生にお願いして課題を出してもらいます。今回の課題は「くずし字に関するサーベイ」と「グラフ構造 x 自然言語処理」という 2 つの課題が与えられ、締切ギリギリのこの時期にやっていました。
博士課程の課題でGraph-Powered Machine Learningを読んでいる。MEAPだからか記載されているコードがガバガバで、自分で補間しながら手を動かしている。もしかしてこのほうが勉強になるのでは説すらある / Manning | Graph-Powered Machine Learning https://t.co/uc4OaolevU
— しゅんけー (@shunk031) 2021年1月20日
くずし字に関するサーベイは以下に記事としてまとめ、公開しております。講義の課題もこのように公開すること前提ですすめると、自然と緊張感のあるものになると思いました。
NAACL 2021 first decision の通知 & Rebuttal
前年に投稿していた NAACL 2021 投稿論文の first decision が通知された時期でした。
去年の今頃はこういうレビューを頂きションボリしていましたが、今年は少しマシになった模様。成長しているかもしれないですが運ゲー状態に近いのは変わらず😂 https://t.co/Aw54ncNxEo
— しゅんけー (@shunk031) 2021年1月21日
指導教員の先生と密に連携して author response を作成し、結果的に全体的なレビュースコアを向上させることができましたが、reject でした(後述)。
Author response、完。今回は短期間ながら先生とかなりやり取りさせていただけたので学びが多かった
— しゅんけー (@shunk031) 2021年1月26日
KDD2021 論文投稿
KDD2019 から投稿し始め、毎年の恒例行事になりつつあります。
論文すげーいい感じになってきて嬉しい、このまま採択されて欲しい気持ちでいっぱいに
— しゅんけー (@shunk031) 2021年2月5日
submitted😤
— しゅんけー (@shunk031) 2021年2月9日
IEEE Access 論文投稿
好きな人(論文ちゃん)を英文校正さんにお願いした
— しゅんけー (@shunk031) 2021年2月19日
ジャーナル submitted 😤
— しゅんけー (@shunk031) 2021年2月23日
学振 DC2 補欠採用
今年一番の嬉しいイベントだったような気がします。
> 貴殿の申請は、独立行政法人日本学術振興会特別研究員等審査会における選考の結果、補欠となっていましたが、このたび採用内定となりました。
— しゅんけー (@shunk031) 2021年2月24日
採用補欠となっていた 学振 DC2 に内定していただきました。「摂動に頑健で解釈可能な深層学習モデルの開発とその解釈性の評価」という課題に取り組みます。弊学ではあまりDCに採用される事例が少なかったため諦めていましたが、これまでやってきたことを評価していただけたようで非常に嬉しいです。
— しゅんけー (@shunk031) 2021年2月24日
学振 DC2 申請書 公開
補欠で採用されるようなギリギリボーダーな人の申請書って実は貴重なのでは?ということで、公開しました。
今回採用に至った学振申請書を公開しました。周辺に相談できる方が少なかったので、自身の申請書を公開することで同じような境遇の方の力になれば幸いです。
— しゅんけー (@shunk031) 2021年2月28日
日本学術振興会特別研究員 (DC2) 申請書・学振 | Shunsuke Kitada https://t.co/iOqHPzUmkA https://t.co/CV6HrJjv4G
申請書を執筆する上でよく見ていた科研費.com さまにも掲載していただきました。
そして非常にお世話になった科研費.comさまにも掲載していただきました。拙い申請書ですが、なにかの助けになれば幸いです。 https://t.co/Wh0BEQ6phf
— しゅんけー (@shunk031) 2021年2月28日
これはいわゆる学振焼肉です。
これが噂の学振焼肉か…? with 申請書をめっちゃレビューしてくれた後輩たち (@ 肉匠さかい 武蔵野桜堤店 in 武蔵野市) https://t.co/6HM3aGuGtl pic.twitter.com/iRTB9YlCp7
— しゅんけー (@shunk031) 2021年3月24日
3 月
人工知能学会全国大会 論文投稿
直近はずっとやってきていたトピックで完成度高めの原稿をいじりまわしていたが、JSAIに出す研究は最近はじめた萌芽感あるやつで、少しビビりながら原稿を書いている。今年はこいつを洗練させていけると良いなぁ。
— しゅんけー (@shunk031) 2021年2月26日
JSAI submitted 😤
— しゅんけー (@shunk031) 2021年3月2日
学振 DC2 採用の話が大学広報にて掲載
法政大学の広報さん @hosei_pr から記事が出ました。弊学のDC2内定は非常に珍しいケースらしく今回このような形で取り上げていただけたようです。 / 理工学研究科の北田俊輔氏が日本学術振興会特別研究員(DC2)に内定 :: 法政大学 小金井キャンパス https://t.co/JV4WHLunaD
— しゅんけー (@shunk031) 2021年3月5日
NAACL2021 結果通知
不採択通知をいただきました。
We are sorry to inform you that the following submission was not selected by the program committee to appear at NAACL-HLT 2021: XXX The selection process was very competitive and unfortunately there were many quality papers that we could not accept. We considered a range of factors including the reviewers' assessment and scores, reviewer discussions, and careful assessment by the area chairs and senior area chairs.
> We are sorry to inform you that the following submission was not selected by the program committee to appear at NAACL-HLT 2021
— しゅんけー (@shunk031) 2021年3月11日
Rebuttalでボーダー付近のレビュースコアを少し上げられたので、良き収穫になったと捉えて次も頑張りたい
— しゅんけー (@shunk031) 2021年3月11日
言語処理学会 2021 発表
#NLP2021 3/17 (水) のP6-14 (15:20〜) にて「半教師あり文書分類のための仮想敵対的学習による注意機構の頑健性および解釈性の向上」を発表します。注意は摂動に弱く説明性を与えないという強めの主張の論文に対して、素直にVATを注意に適用すると頑健性と解釈性双方が向上することを確認した話です。
— しゅんけー (@shunk031) 2021年3月16日
#NLP2021 3/18 (木) P9-14 (14:00〜) にて共著の発表「キャプション生成時低品質データ事前検知の試み」 w/ @ka_nd9 があります。実世界の運用を想定した画像キャプションにおいて、キャプション生成が難しい画像を予測する「キャプション生成を諦める君」について検討しました。よろしくお願いします
— しゅんけー (@shunk031) 2021年3月18日
カルタゴ大セミナー登壇
言語処理学会ポスター発表おわりました!たくさんの方に聴いてくださり、また議論していただきありがとうございました。これからチュニジア カルタゴ大のセミナーで発表します(めっちゃ訛っててやばいかも…がんばり豆大福!)
— しゅんけー (@shunk031) 2021年3月17日
I have FINALLY published the slides for the 1st Univ. Carthage - Hosei International Joint Webinar in Mar, 2021 😂 😂 😂 / Practical and Interpretable Deep Learning Techniques in Our Iyatomi’s Lab - Speaker Deck https://t.co/EMiepJ8Yje
— しゅんけー (@shunk031) 2021年7月1日
GoTo 箱根
最高の人生はここから始まります♨ (@ 箱根湯本駅 in 箱根町, 神奈川県) https://t.co/B6Ys0OfHI8
— しゅんけー (@shunk031) 2021年3月26日
IEEE Access 不採録通知
不採録通知をいただきました。
> ... Therefore, in order to uphold quality to XXXX standards, an article is rejected even if it requires minor edits.
— しゅんけー (@shunk031) 2021年3月29日
😥
4 月
2021年度もよろしくお願いします (@ 法政大学 彌冨研究室) https://t.co/gf5SjuLuDx
— しゅんけー (@shunk031) 2021年4月2日
学振 DC2 採用の話が学科広報にて掲載
応用情報工学科のHPにも掲載していただきました。ありがとうございます。引き続きがんばります / 北田俊輔さん(D2), 日本学術振興会特別研究員に | 法政大学 理工学部 応用情報工学科 https://t.co/YxtKN9q2zB
— しゅんけー (@shunk031) 2021年4月8日
AppBrew テックブログへ記事寄稿
AppBrewさんに声を掛けていただいて寄稿しました。機械学習x広告クリエイティブの最新の研究事例のほか、実際に広告プロダクトとして運用している中国のAlibabaやTencentの事例を取り上げました / “コスメプラットフォームLIPSと広告クリエイティブ: 最新の研究事例から見…” https://t.co/H02pX1APtv
— しゅんけー (@shunk031) 2021年4月28日
「機械学習技術によって実際のサービスの課題をどのように解決できるかを紐解く力」はこれから必要だと思っていたので、非常に嬉しいコメントで励みになりました。
— しゅんけー (@shunk031) 2021年4月29日
AppBrewさんとは非常にスムーズに連携できて、副業等々もしやすそうだなという印象でした! https://t.co/aSolTLK9XR
5 月
CyberAgent AI Lab 博士インターン開始
2ヶ月ほどお世話になります🙇 (@ Abema Towers in 渋谷区, 東京都) https://t.co/WH7akFmK8G pic.twitter.com/ufXwMIIHHk
— しゅんけー (@shunk031) 2021年5月6日
母の日に母親に iPhone 11 をプレゼントしたいい話
母の日に、母が欲しがっていた iPhone 11 のグリーンを送ってあげたらめちゃめちゃ喜んでくれたみたい。これまでは僕がアキバで 1000 円ぐらいで買った iPhone 5 を使っていて不便そうだったので(当たり前)、少し親孝行ができてよかった
— しゅんけー (@shunk031) 2021年5月9日
令和 2 年度博士課程進学に伴う採用時返還免除内定者の決定
D1 のときに借りていた日本学生支援機構の第一種奨学金がこの時点で免除確定になりました。ありがとうございます。
KDD2021 結果通知
不採択通知をいただきました。
We regret to inform that your paper: Paper ID: XXX Paper title: YYY has not been accepted for presentation at SIGKDD 2021.
ACM系のトップカンファ、採択率余裕で20%切るから戦うのしんどいけど採択されたら世界中の企業に注目されるし、またあの舞台で発表したいという気持があるから投稿するのをやめられない😈😈😈
— しゅんけー (@shunk031) 2021年5月20日
IEEE Access 論文投稿
メンタルが強すぎるため we regret を受け取った日のうちに新しい論文を submit した。今度こそ頼むぞ〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
— しゅんけー (@shunk031) 2021年5月18日
新垣結衣、星野源と結婚
ママァーーーーーー😭😭😭😭😭 / 新垣結衣と星野源が結婚を発表(オリコン)#Yahooニュースhttps://t.co/a3sfoB8vr6
— しゅんけー (@shunk031) 2021年5月19日
CIKM2021 論文投稿
submitted 😤
— しゅんけー (@shunk031) 2021年5月27日
6 月
人工知能学会 2021 発表
今週から始まる #JSAI2021 で @YoshifumiSeki さんと取り組んでいる「広告クリエイティブ評価のための深層確率埋め込みの学習」を発表します。始めたばかりの研究なのでぜひ皆さんと議論させてください!https://t.co/pAmuTeqBjp
— しゅんけー (@shunk031) 2021年6月7日
#JSAI2021 広告 AI 懇親会面白いな、久しぶりに面白い飲み会に参加してる感ある
— しゅんけー (@shunk031) 2021年6月9日
今年も #JSAI2021 「広告とAI」slack盛り上がってる👀 オーガナイザーやチェアの方たちのテキストベースの議論や盛り上げが上手すぎる、心理的に質問もしやすい感じになっているので良い https://t.co/IbvBlG2ZsP
— しゅんけー (@shunk031) 2021年6月10日
IEEE Access 論文採録
採録通知をいただきました。
21-Jun-2021 Dear Mr. Kitada: Your manuscript entitled "Attention Meets Perturbations: Robust and Interpretable Attention with Adversarial Training" has been accepted for publication in IEEE Access. The comments of the reviewers who reviewed your manuscript are included at the foot of this letter. We ask that you make changes to your manuscript based on those comments, before uploading final files.
Our journal paper "Attention Meets Perturbations: Robust and Interpretable Attention with Adversarial Training" is accepted for publication in IEEE Access #IEEEAccess 🎉 The accepted version of the article and the #allennlp based code will be available soon. Stay tuned 🤗
— しゅんけー (@shunk031) 2021年6月22日
Our paper is published in @IEEEAccess and we uploaded the final version of the paper on @arxiv. The code is now publicly available on @github. We also prepared an introduction page of our work 😉:
— しゅんけー (@shunk031) 2021年7月7日
📄 https://t.co/oi8Sba5zWf
📝 https://t.co/hMAAR1qwCt
💻 https://t.co/uHJrP0R8Vf
You can find the introduction page: https://t.co/eYaDTakxIZ
— しゅんけー (@shunk031) 2021年7月7日
CyberAgent AI Lab 博士インターン最終出社
最終出社でした!!!お世話になりました!!
— しゅんけー (@shunk031) 2021年6月30日
7 月
CyberAgent AI Lab 協働研究員 開始
本日付けで CA AI Lab の協働研究員としてお世話になります。学振特別研究員として取り組んでいる基礎研究から得た知見を元に、実世界への応用研究として社会実装していきたいです。よろしくお願いします! https://t.co/j86LhqgL7k
— しゅんけー (@shunk031) 2021年7月1日
小倉唯 ライブ
久しぶりにオタク、やります (@ パシフィコ横浜 in Yokohama, Kanagawa) https://t.co/QzjcFU8jLv
— しゅんけー (@shunk031) 2021年7月4日
GoTo 軽井沢
対戦、よろしくお願いします (@ 軽井沢駅 in 軽井沢町, 長野県) https://t.co/kUwX5WxS6J
— しゅんけー (@shunk031) 2021年7月13日
軽井沢の草原と、オタク pic.twitter.com/JxpG6S33SP
— しゅんけー (@shunk031) 2021年7月16日
次のジャーナル投稿する手前で少し研究から離れてみたけど、気分転換ってありえないほど大事だなぁと思った次第。パソコンを持たずにフラ~~っとしたのが良かったかもしれないが、そのおかげで未読通知が溜まっている…🤣 pic.twitter.com/G12HRyH3oM
— しゅんけー (@shunk031) 2021年7月17日
8 月
NTT 人間情報研 インターン開始
8/16からお世話になっていた NTT人間情報研究所のインターンが終わりました! @kyoun さんにご指導していただいたおかげで、これまで取り組んだことがなかった分野を開拓できました。フルリモートだったのが残念でしたが、丁寧にサポートして頂き非常にやりやすかったです 🙌 https://t.co/mxAx6PibPW
— しゅんけー (@shunk031) 2021年9月10日
日当9000円になっておそらく初めてのインターン生でしたがちゃんと振り込まれてました(当たり前)
— しゅんけー (@shunk031) 2021年11月6日
CIKM2021 結果通知
不採択通知をいただきました。
Dear Shunsuke, Thank you for your submission to the CIKM 2021 Applied Research Track. Unfortunately, we did not accept your paper for presentation at the conference: XXX: YYY
YANS 2021 発表
yans2021 のラウンドテーブルで「twitter よく見てます」みたいな話になると途端にインターネットのオタクになってしまう
— しゅんけー (@shunk031) 2021年8月30日
9 月
IEEE Access 論文投稿
以下の論文に関する拡張についての論文を投稿しました。
AAAI2022 論文投稿
submitted 😤
— しゅんけー (@shunk031) 2021年9月9日
(実はインターン中にジャーナル論文1本、カンファレンス論文1本投稿しました。フルリモートで即切り替えて論文執筆したのでその点フルリモートは良かったです。きっかり就業時間が決まっていたのも切り替えやすかったですね。体力の限界が分かったのでもうやりませんが…🤣)
— しゅんけー (@shunk031) 2021年9月10日
IEEE Access 論文投稿
KDD2020 から投稿を続けているネタを IEEE Access へ投稿することに。
ようやく手元にあった原稿たちをすべて投稿し終えて久しぶりに何もない状態になったので、少し新しいところを勉強し始めた(とりあえず論文を50本ぐらい吸収したい)(できるか?)
— しゅんけー (@shunk031) 2021年9月19日
花粉症の舌下療法を開始
花粉症 の 舌下免疫療法 開始✌️
— しゅんけー (@shunk031) 2021年9月21日
今日から シダキュア 2000 から 5000 に pic.twitter.com/TRfFOGO8t7
— しゅんけー (@shunk031) 2021年9月28日
10 月
IEEE Access 不採録通知
再投稿が許されるタイプの major revision 相当の不採録通知でした。
06-Oct-2021 Dear Mr. Kitada: I am writing to you in regards to manuscript # Access-XXXX-YYYY entitled "ZZZZ" which you submitted to IEEE Access. Please note that IEEE Access has a binary peer review process. Therefore, in order to uphold quality to IEEE standards, an article is rejected even if it requires minor edits.
GoTo 金沢
人生 (@ 金沢城公園 in 金沢市, 石川県) https://t.co/rbFoKeaiDu pic.twitter.com/GWDf7tZccQ
— しゅんけー (@shunk031) 2021年10月18日
GoTo 白川郷
落ち込んだときはとりあえず白川郷に来るとどうでも良くなりそう pic.twitter.com/AYe9tHCqpf
— しゅんけー (@shunk031) 2021年10月19日
AAAI2022 結果通知
不採択通知をいただきました。
Dear Shunsuke KITADA, We regret to inform you that your AAAI-22 submission XXXX did not advance to the second phase of the 2-phase review process and hence has been rejected. There were over 8000 submissions to AAAI this year. In light of the fact that the acceptance rate for AAAI is typically around 25%, only about 56% of the papers advanced to Phase 2 of the review process based on the Phase 1 reviews. During Phase 1, each submission was initially assigned to 2 reviewers. Every effort was made, using the most uptodate information available to us, to avoid conflicts of interest throughout the entire review and decision process.
WWW2022 論文投稿
AAAI2022 不採択だった原稿を更新して The Web Conference (通称 WWW) へ投稿しました。
IEEE Access 不採録通知
再投稿もだめなパターンでした。他のジャーナルを探さないと。
Dear Mr. Kitada: I am writing to you in regards to manuscript # Access-XXXX-YYYY entitled "ZZZZ" which you submitted to IEEE Access. In view of the criticisms of the reviewer (s) found at the bottom of this letter, your manuscript has not been recommended for publication in IEEE Access. Unfortunately, we will not accept resubmissions of this article.
11 月
ジャーナル投稿に向けて準備
ツイートからは何もやっていなかったような雰囲気を感じるのですが、slack 等を見返すとジャーナル投稿に向けて原稿を準備していたようです。
GoTo 栃木足利
ゲーミングデスクトップバソコンみたいなのを見に来た💡 (@ あしかがフラワーパーク 東ゲート in 足利市, 栃木県) https://t.co/vxFauJahF8 pic.twitter.com/mmaR66YwAR
— しゅんけー (@shunk031) 2021年11月13日
12 月
論文全然通らないなぁ、みたいな気持ちになっています。
最近はもうずっとしんどくてずっとトンネルの中という感じ…。ケンキューって難しい
— しゅんけー (@shunk031) 2021年12月2日
WWW 2022 first decision の通知 & Rebuttal
AAAI 2022 では比較的ポジティブなコメントを貰っていたのですが、WWW 2022 のレビューでは厳し目のコメントが多かったです。
アドベントカレンダー 記事執筆
はてなブログに投稿しました #はてなブログ
— しゅんけー (@shunk031) 2021年12月8日
学振特別研究員が2021年に特別研究員奨励費で購入した物品のオススメを晒してみる - May the Neural Networks be with youhttps://t.co/r2sKDzOpKh
はてなブログに投稿しました #はてなブログ
— しゅんけー (@shunk031) 2021年12月22日
先生の「まずは論文の骨子を箇条書きで書いてみて」に対応する: 論文執筆の第一歩 - May the Neural Networks be with youhttps://t.co/L1J2Io4rpN
小倉唯ライブ
昼公演夜公演どちらも参加する疲れるようになってきました。年かな…?
小倉唯 昼公園☀ (@ 神奈川県民ホール1階席) https://t.co/qo1Myj06xd
— しゅんけー (@shunk031) 2021年12月11日
小倉唯 夜公演🌙 (@ 神奈川県民ホール1階席) https://t.co/lUFyW98bta
— しゅんけー (@shunk031) 2021年12月11日
関内二郎、いきたかった。
オタクのライブ前に関内二郎行ってニンニクマシマシをキメようとしたら、本日休業。
— しゅんけー (@shunk031) 2021年12月11日
IEEE Access 論文投稿
Major revision 相当だった原稿を再投稿しました。
ジャーナルへ revision を投稿して最高の2021年の仕事納めを実現しました(年末に論文を投稿するな💢)
— しゅんけー (@shunk031) 2021年12月28日
論文投稿
今年のカンファレンス・ジャーナルそれぞれの投稿結果をまとめます。
カンファレンス論文
NAACL2021
- レビュー結果
- [R] 2.5, 3, 3 -> (after rebuttal) -> 2.5, 3.5, 3.5
- お気持ち
- Rebuttal 前はボーダーラインだった reviewer #2 と #3 をポジティブな方向に持っていけたのは良かったです 一方で reviewer #1 のネガティブな気持ちをひっくり返すことはできませんでした
KDD2021
- レビュー結果
- [R] WA, SR, WR, WA
- お気持ち
- KDD2020 -> WSDM2021 と投稿してきて、WSDM2021 のレビュー結果 がそれなりに positive だったため、今年の KDD は通るかなぁと思っていたのですがだめでした。難しいですね
CIKM2021
- レビュー結果
- [R] R, WR
- お気持ち
- 上記 KDD2021 の再投稿だったのですが、深みにハマってしまったらしくどんどんレビュー内容が悪くなっていきました
- このままカンファレンスに投稿し続けるのは良くないと考え、指摘内容を更新した後にジャーナルに投稿することにしました
AAAI2022
- レビュー結果
- [R] BA, BA
- お気持ち
- CyberAgent AI Lab での成果を投稿しました。3 ヶ月で仕上げた内容でしたが比較的ポジティブなコメントが多かったです。
- 一方で採択へ後押しする決め手がなかったために Phase 1 で reject になってしまいました。
- こちらは現在 WWW へ再投稿しています。
ジャーナル論文
卒業要件として先生曰くジャーナル 3 本程度が必要だとおっしゃっていたので、個人的にはカンファレンスに投稿したかった気持ちを抑えてジャーナルに投稿していくことにしました。投稿先は査読が早いと噂の IEEE Access を選択し、手元にある原稿を投稿していく方針で進めました。 IEEE Access は binary decision *1 を採用しており、minor/major revision 相当であっても一旦 reject になり、再投稿が許されます。ある程度のボーダーを下回ると再投稿が許されない不採録の決定もあります。
IEEE Access (1)
- レビュー結果
- [R (major revision 相当)] R (updates required before resubmission), R (updates required before resubmission), A (minor edits)
- -> [A] Accept (minor edits), Accept (minor edits)
- お気持ち
IEEE Access (2)
- レビュー結果
- [R (major revision 相当)] R (updates required before resubmission), R (updates required before resubmission) i
- お気持ち
IEEE Access (3)
- レビュー結果
- [R] R (do not encourage resubmit), R (do not encourage resubmit)
- お気持ち
まとめ
- D2 が終わりました。折返し地点の気がしません。
- 論文はたくさん書けるようになってきましたが、クオリティの面はまだまだでした。
- D3 も頑張りたいです。シューカツをやらなくてはならない気がしています。企業で研究できそうなポジションがありましたらお声がけください。
- 少しずつお声がけ頂いております。ありがとうございます。
少しずつ裏ルートなシュウカツ宣伝が届くようになってきて、学生生活本当に終わりそうな雰囲気を感じる………………こんな楽しい毎日………終わるのか……?
— しゅんけー (@shunk031) 2021年12月20日
*1:Rapid Peer Review – IEEE Access https://ieeeaccess.ieee.org/about-ieee-access/rapid-peer-review/
*2:Attention Meets Perturbations: Robust and Interpretable Attention With Adversarial Training | IEEE Journals & Magazine | IEEE Xplore https://ieeexplore.ieee.org/document/9467291
*3:[2104.08763] Making Attention Mechanisms More Robust and Interpretable with Virtual Adversarial Training for Semi-Supervised Text Classification https://arxiv.org/abs/2104.08763
先生の「まずは論文の骨子を箇条書きで書いてみて」に対応する: 論文執筆の第一歩
こんにちは @shunk031 です。 年末年始は国内学会の締め切りが多く、研究室内で初めて論文を書く人たちが増えてくる時期です。 本記事はそのような論文執筆が初めての弊研 (彌冨研究室) B4 や M1 に向けて書きましたが、一般的に論文の書き始めに通じるところがあると思います。
この記事は 法政大学 Advent Calendar 2021 22 日目の記事です。

弊研では恒例ですが、研究が進んできて結果がまとめられそうな段階になってくると 先生 に以下のようなことを言われます。
「まずは論文の骨子を箇条書きで書いてみて!」
本記事は「論文の骨子とはどのようなものか」「箇条書きで骨子を書く場合の注意点はなにか」に焦点を当てます。 この記事では言及できない、基礎的な(科学)論文執筆の技法が存在します。 それらを補うため、弊学科・弊研究科の学生の場合は 科学技術文技法 をまずは履修してください *1*2*3。
以下は目次です:
忙しい人向けまとめ
忙しい人向けに「論文の骨子を箇条書きで書いてみて」と言われたときにやる 3 つのことをまとめます:
- まず論文の大枠を箇条書きで
3 〜 4個書きます- これらは トピックセンテンス と呼ばれます
- この大枠が非常に大事ですが、肩の力を抜いて気軽に適当に書きます
- それぞれのトピックセンテンスに、更に説明する文を
2 〜 3個書きます- これらは サポートセンテンス と呼ばれます
- 各トピックセンテンス内ではそのトピックの話だけをするようにサポートセンテンスを書きます
- 最後にまとめになる文 1 個書きます
- これは 小結論センテンス と呼ばれています
- トピックセンテンスから小結論センテンスまでのまとまりは
パラグラフと呼ばれています

論文の骨子とはどのようなものか
先生から「論文の骨子」と言われたら、まずは「イントロの流れ」やそのアウトライン *4 のことについて言われていると考えてください。 以下はその「イントロの流れ」を一から作るためにはどうすればいいかを私個人が考えていることを書きます。
アカデミックライティングの基本:パラグラフライティング
パラグラフライティングとは、1つの話題について書かれたパラグラフを組み合わせて、論理を展開していく文章技法です *5。 パラグラフライティングのポイントは「各段落の先頭行だけを抜き出せば正しい要約ができあがるようにする」ことです *6。 この「 各段落の先頭行 」を「 トピックセンテンス 」といい、トピックセンテンスを集めたものが「 論文(イントロ)の骨子の元 」になりうると私は考えています。 この論文の骨子の元となるものに肉付けしていくことで、「 論文の骨子 」が完成します。
論文の骨子以外に先生から要求されるものとして、introduction で示した仮説や提案法の有効性をどのように示すかの「 実験の骨子 」があります。 これは現状出ている結果や主張したい話を評価できるような実験をいくつか考える必要があります。 この記事では実験の骨子の書き方については述べません。
実際の論文はどうか:実例でトピックセンテンスを確認
Tan et al, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks"*7 を例に取り上げます。 深層学習による画像認識分野の研究している方だとよく聞く論文だと思います。 良い論文はトピックセンテンスが骨子の元になります。 以下を読むだけで論文の全体がざっくりと理解できるはずです:
- Scaling up ConvNets is widely used to achieve better accuracy.
- In this paper, we want to study and rethink the process of scaling up ConvNets.
- Intuitively, the compound scaling method makes sense because if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the biggerimage.
- We demonstrate that our scaling method work well on existing MobileNets and ResNet.


自然言語処理分野で現在注目されている論文はどうでしょうか?Devlin et al, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"*8 は以下のようなトピックセンテンスが並びます。上から下へ流れるように話が進んでおり、ロジックが行ったり来たりしていません。上記で例に挙げた EfficientNet の論文同様に、トピックセンテンスを読むだけで論文の全体がざっくりと理解できます:
- Language model pre-training has been shown to be effective for improving many natural language processing task.
- There are two existing strategies for applying pre-trained language representations to down-stream tasks: feature-based and fine-tuning.
- We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches.
- In this paper, we improve the fine-tuning based approaches by proposing BERT:Bidirectional Encoder Representations from Transformers.


先生から「論文の骨子を書いてみて」と言われたらビビらずに、まずトピックセンテンスとなりうるような文 (通常 3〜4 文) を考えましょう。 「論文」を書くとなると非常に大変そうですし、難しそうです。一方で、「3、4 文で研究説明できる良うにとりあえず書いてみてよ〜」と言われたらできそうです。やればできます*9 。
箇条書きで骨子を書く場合の注意点

トピックセンテンス となる文ができたら、それらに肉付けしていくことで、論文の骨子を作っていきます。
先生とは Microsoft Word でやり取りすることが多いので、Word でファイルを作成するか、Google Doc 等を作成して Word に export することを検討してください。
ここでファイル名は非常に重要です。 202X-YY-ZZ_山田太郎_論文骨子 のようなファイル名にしましょう。
先生は複数人とやり取りするため、誰の骨子かわかりやすくすべきです。
更にこのような丁寧な命名規則は自分で論文を書いていく中でも時系列順で編集履歴がわかりやすくなります。
箇条書きで トピックセンテンス となりうる文を書いたら、そのセンテンス郡をトップレベルの箇条書きにします。 トピックセンテンスをより細かく説明するサポートセンテンスは一つインデントを下げて書くようにします。 こうすることで、文の構造を明示的にわかりやすくする役目があると私は考えています。 上図の 緑色のハイライトされた文 はサポートセンテンスであり、 黄色でハイライトされた文 は 緑色でハイライトされた文 を更に説明する役目があると言えます。 サポートセンテンスでトピックセンテンスを適宜説明したら、最後に 小結論であるセンテンス を書いて締めます。 これらトピックセンテンス、サポートセンテンス、小結論センテンスのまとまりをパラグラフと言います。
骨子からイントロを組み立てる
ここまでくればほとんどイントロ( = introduction; 論文の導入部分)は完成です。 トピックセンテンスやサポートセンテンスに適宜文献を引用したり、主な実験結果の数値を載せたりします。 イントロの最後に研究の貢献を箇条書きでまとめることで、論文の主張したい部分を強調することができます。
イントロの流れ以外の骨子
箇条書きで骨子を書く際のトピックセンテンス 4 行からのそれぞれに対する 3 行ほどのサポートセンテンス・小結論センテンスという流れは、イントロ以外でも同じです。 例外はあると思いますが、この流れをまずは守ることが重要です。センテンス 1 つのパラグラフを書いてしまったときはおかしいかな?と感じるようになると良いです。
関連研究セクションでも トピックセンテンス -> サポートセンテンス -> 小結論センテンス のまとまり(パラグラフ)から構成されます。
自身の研究に関連する分野を 2〜3 個ピックアップしてタイトルを付け、複数のパラグラフを書いて自身の研究と関連する研究の差分や立ち位置がわかるように書けば、もうほとんど完成です *10。
Python での実装は得意だけど、論文はちょっと… な人向けのイメージ
論文は自然言語の集まりですが、プログラミング言語のような機械言語のようにみなすことができます。 以下は Python 風擬似コードで論文の構成をイメージしたものです。

論文もプログラミング言語同様 スコープ があります。 各パラグラフはそれぞれ関数とみなすことができ、その関数で最初に提起された話題(= トピックセンテンス)しか扱いません。 関数内から他の関数の話題には触れられません。例外としてその分野の共通知識や問題点等の話題は触れることができます。 これはこうした話がグローバルスコープ・空間にあると見なせるからです。 このような スコープ の意識を持っておくと、論文を執筆する際に、話題が行ったり来たりするのを防ぐことができるかもしれません。
まとめ
先生から まずは論文の骨子を箇条書きで書いてみて と言われた弊研の学生に向けて、私が考える骨子の書き方を示しました。
まずは、研究の大きな流れを 3〜4 文で書き、それぞれの文により細かい説明文を 2〜3 文追加することで、「骨子」が完成すると考えています。
このような書き方はいわゆるパラグラフ・ライティングと呼ばれる方法になります。本記事で紹介した方法以外にもより良い書き方があると思うので、ぜひ私に教えて下さい。(そして一緒に論文を書きませんか?)
*1:弊学科以外でもアカデミック・ライティングの授業は必ずあるはずなので受講することをおすすめします。更に世の中にはアカデミック・ライティングについての書籍が複数あります
*2:アカデミック・ライティング書籍おすすめ (1); 洋書ですが非常に平易な英語で書かれており具体的で非常にわかりやすいです。/ Science Research Writing For Non-Native Speakers Of English Hilary Glasma... https://www.amazon.co.jp/dp/184816310X
*3:アカデミック・ライティング書籍おすすめ (2); 網羅的にアカデミック・ライティング全般を学べる本です。辞書的に持っておくことをおすすめします。 / ネイティブが教える 日本人研究者のための論文の書き方・アクセプト術 (KS 科学一般書) エイドリアン・ウォールワーク https://www.amazon.co.jp/dp/4065120446
*4:「骨子」のことを「アウトライン」として説明している良いページ。参考になります。/ レポートの構成とパラグラフ・ライティングを知る | 名古屋大学生のためのアカデミック・スキルズ・ガイド https://www.cshe.nagoya-u.ac.jp/asg/writing03.html
*5:パラグラフ・ライティングについて | https://ichinomiya-h.aichi-c.ed.jp/ssh/kyouzai/paragurahu.pdf
*6:パラグラフライティングの作法 - 書き手にもメリットのある文配置ルール - | Systems Android Robotics http://www.ams.eng.osaka-u.ac.jp/user/ishihara/?p=566
*7:[1905.11946] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks https://arxiv.org/abs/1905.11946
*8:[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805
*9:そしてようこそ論文執筆沼へ。締め切りまで走りきって、原稿提出したあとに「「最高」」 になりましょう。残念ながら僕はこの「最高」に取り憑かれているようです。
*10:関連研究のセクションって書くの難しいですよね。未だによくわかりません。
学振特別研究員が2021年に特別研究員奨励費で購入した物品のオススメを晒してみる
こんにちは @shunk031 です。ViT *1 が流行っていますね。パッチに分割して Deep でポン!がもう少し流行りそうです。個人的には ViT のほうが CNN よりもロバストな雰囲気を感じており *2、そのあたりの性質をうまく利用したモデルが作れたら楽しいかなと妄想しています。
この記事は 法政大学 Advent Calendar 2021 8 日目の記事です。

学振特別研究員と特別研究員奨励費
私は今年度から 学振特別研究員 DC2 (いわゆる学振 DC2)に採用していただきました *3。 弊学科からはおそらく初めての採用で、大学広報や学科のホームページにも取り上げていただいたりと、ちょっとしたお祭り騒ぎになっていました。
特別研究員の採用を経て、特別研究員奨励費 の申請を出すと、ある程度の研究費が科研費として交付されます *4。 どの程度の研究費が交付されているかについては KAKEN のページ等を確認するとわかります。 例えば私の場合、配分額は 1,500 千円のようです *5。
本記事は JSPS 科研費 21J14143 の助成を受けて購入した、特に研究に役立った物品を紹介します。 特別研究員奨励費は研究を始めたばかりの人間が研究費として自由に使える額としては比較的大きい方だと思います。 いざ交付していただくと具体的にどのように使っていくかを考えるのは非常に難しいです。 本稿が来年度以降に学振 DC に採用された方の助けになれば幸いです。
特別研究員奨励費で買ってよかったもの
以下は特別研究員奨励費で購入して特に研究に役立った物品を晒します。各物品に対する所感は以後の記事で紹介したいです。
書籍
- 辞書的に利用したいと思い購入しました。いつも新しい発見があります。

")
- 見た目とは異なり中身は非常に平易に深層学習について説明されていました。深層学習を学んだことがない人に自身の研究を説明するのに役立ちます。
")
- 論文のクオリティを上げたいと考えて購入しました。自身の書く英語は誤用が多かったです。。。

- 更にこちらも購入。
aやtheといった冠詞を中心にその使用例がわかりやすく解説されています。読んでいて新たな発見ばかりで面白いです。

- 機械学習モデルを何かしらのシステムに組み込んで、その効果を検証したいという気持ちに対して非常に平易かつ直感的に解説されていました。何回も読み返したい本です。研究でも正しく効果を検証していきたいですね。

- 私自身の研究内容が深層学習モデルの解釈に関するもので、興味があったので購入しました。ブラックボックスなモデルをうまく解釈する方法はやっぱり面白いです。

- 埋め込み表現まわりの話で最新のトピックまでカバーされていました。非常に読みやすく、きれいにまとまっています。
")
- 博士課程に入ってから書くことが多いため、「書く」ことに対して一般的な良い方法が知りたかったために購入しました。当たり前でもできていないことが多く、振り返って実践したい話が多数見つかりました。

電子機器
 3.5インチ WD101EFBX-EC 【国内正規代理店品】")
- 僕も iPad すなるものを購入してみました。主に論文を読む用です。パソコンから zotero + zotfile *6 で google drive に論文を追加しておいて、iPad からは Adobe Acrobat で開いてハイライトを入れたりメモを入力したりしています。僕は論文を読むときあまり書き込みをせずに重要そうな箇所のみハイライトするような運用でして、この構成で現在は落ち着いています。
 - シルバー")
- Stay Home で Macbook を持ち歩かなくてよくなったため購入しました。型落ちですがパワフルで論文を書く程度の作業では十分です。
")
おわりに
本記事は JSPS 科研費 21J14143 の助成を受けて購入した、特に研究に役立った物品の一部を紹介しました。 上記以外にも学術論文の英文校正費や掲載費にも特別研究奨励費を使用させていただいており、充実した研究生活を送っております。 来年度以降も頂いている研究費を最大限活かし、良い研究を実行できるよう努力していきます。
*1:[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale https://arxiv.org/abs/2010.11929
*2:[2111.05464] Are Transformers More Robust Than CNNs? https://arxiv.org/abs/2111.05464
*3:僭越ながら学振 DC2 の申請書を公開しております:日本学術振興会特別研究員 (DC2) 申請書・学振 | Shunsuke Kitada http://shunk031.me/post/dc2/
*4:学振特別研究員は研究奨励金 (月 20 万程度) と特別研究員奨励費 (毎年度 150 万円以内の研究費) が支給されます。> 申請資格・支給経費・採用期間 | 特別研究員|日本学術振興会 https://www.jsps.go.jp/j-pd/pd_oubo.html
*5:KAKEN — 研究課題をさがす | 摂動に頑健で解釈可能な深層学習モデルの開発とその解釈性の評価 (KAKENHI-PROJECT-21J14143) https://kaken.nii.ac.jp/ja/grant/KAKENHI-PROJECT-21J14143/
*6:こちらを参考にしました / 文献情報と PDF ファイルをうまく管理する (zotero と zotfile)・大舘暁研究室 https://ohdachi.github.io/ohdachi_lab/researches/2018/02/02/zotero_zotfile.html